Intuitive User Interfaces and Visualization Tools
Intuitive user interfaces and robust visualization for scientific research and development.
Pandia Software’s core user interface design principles center around easy-to-use experiences that simplify complex tasks into straightforward, step-by-step interactions for all users. We have expertise in developing cross-platform user interfaces in a variety of languages and libraries including Java Swing, JavaFX, C# .NET, JavaScript with jQWidgets, and eNotebooks in Python, R, and MATLAB, which seamlessly integrate with online data management and analysis services.
In addition, we have in-depth knowledge customizing and integrating popular data visualization frameworks, such as Matplotlib, VisIt, ParaView, and JOGL, as well as creating new interactive visualization views using the Java Swing and JavaFX graphics packages. We also utilize geographical plotting libraries, such as Leaflet.js and Folium, for visualizing your data on interactive maps. In combination with our user interface designs, users will be able to quickly and easily explore important features in their data and generate animations for sharing with colleagues.



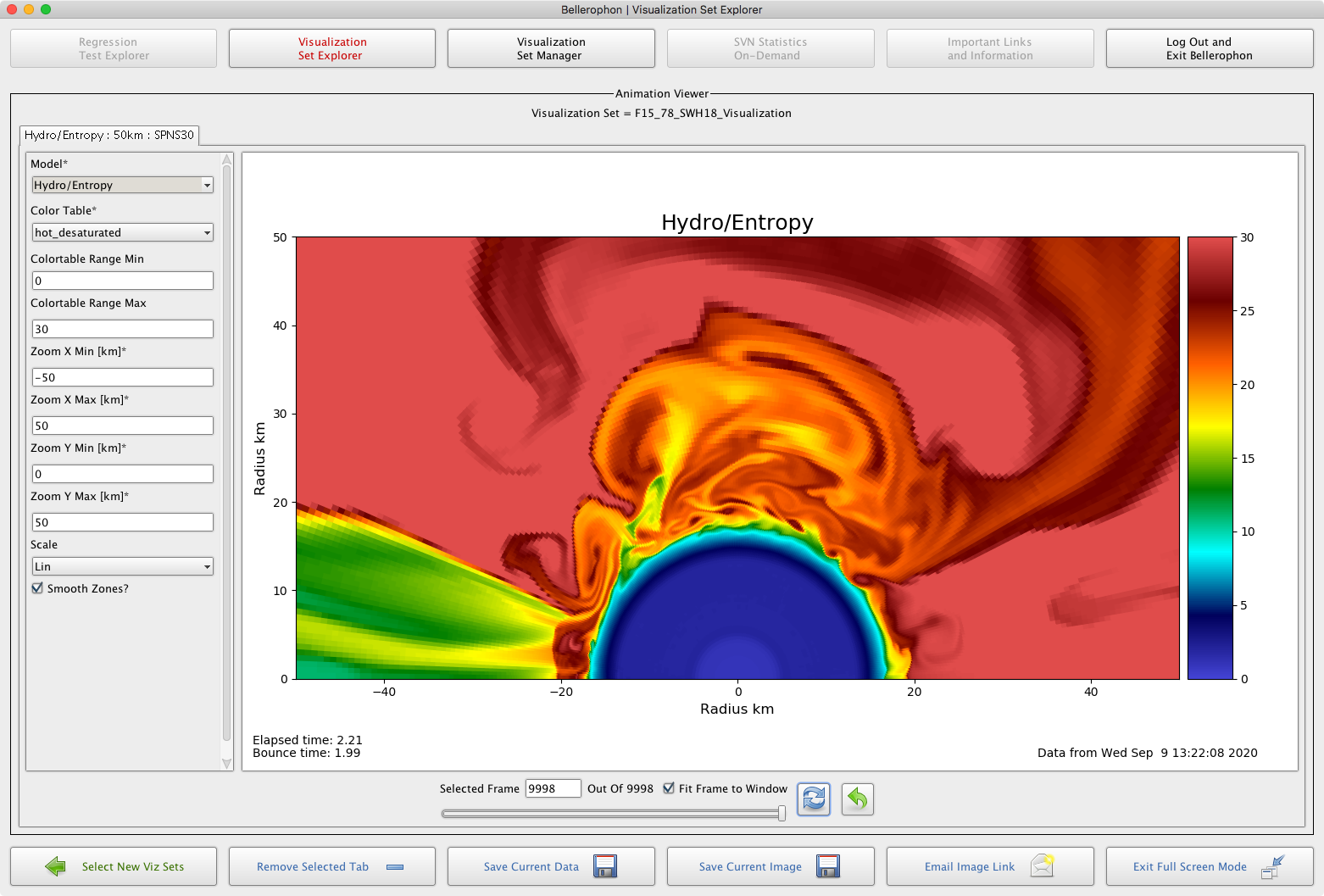



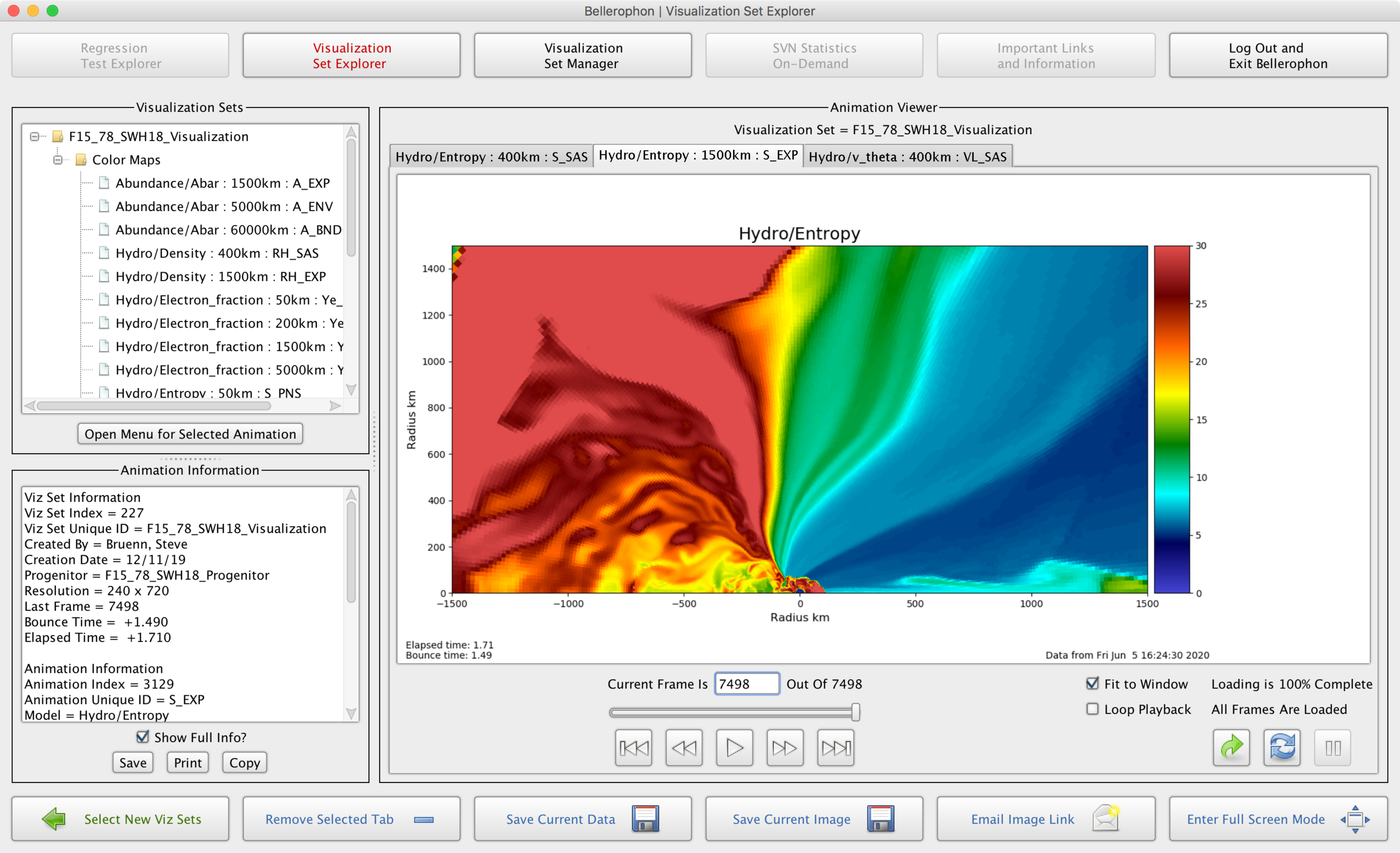
HPC Computational Workflow Environments
Computational workflow systems that integrate the power of high performance computing with the ease of intuitive user interfaces.
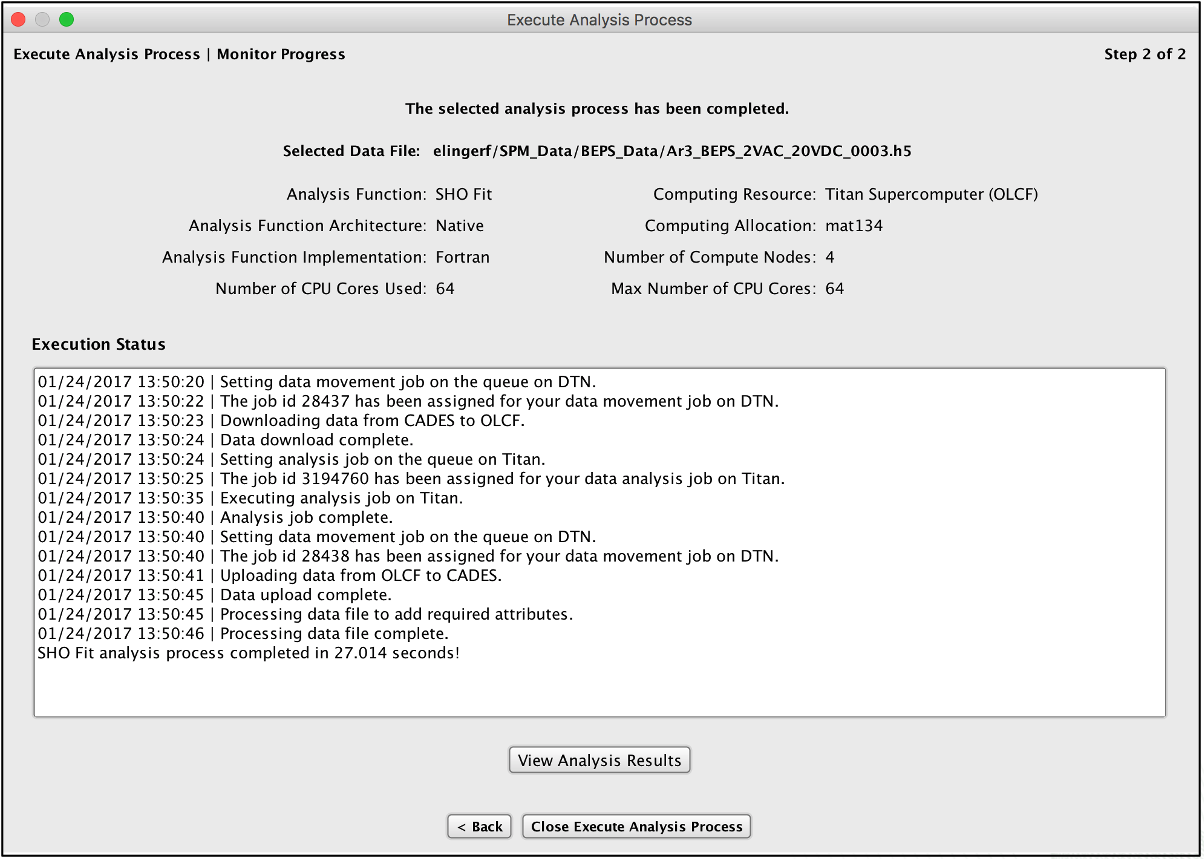
As a Technical Staff Member at ORNL, Eric Lingerfelt of Pandia Software led the design and development of several high performance computing workflow systems. These award-winning systems seamlessly integrate with high performance computing platforms (e.g., Titan, Jaguar, Cori, XSEDE), petabyte-scale, parallel Lustre filesystems, high speed data transfer mechanisms, secure web services, and databases with real-time analysis, visualization, data management, machine learning algorithms, and massively parallel theoretical simulations. The Bellerophon and BEAM software products are excellent examples of accessing these powerful capabilities through intuitive desktop applications.
Does your team have large scale data sets that are not easy to analyze on a laptop? Maybe your team has a parallel code that is difficult to execute using command line options? Or, are you waiting hours or even weeks to analyze and visualize your results? Pandia Software has software solutions ready to go and customize for your needs!

Cloud-based Data Analysis and Management Tools
Distributed data analysis and management utilizing the cloud and machine learning algorithms.
Eric Lingerfelt of Pandia Software led the design and development of multiple software systems with complex back end components and services containerized for cloud environments such as ORNL’s CADES and XSEDE’s JetStream. Systems such as Bellerophon, BEAM, and CINA utilize the cloud for web services, data analysis, data/metadata management and storage, computational modeling, and application of machine learning algorithms for end-to-end discovery workflows that greatly decrease the time and expense of your science through the integration and automation of your scientific requirements. By utilizing the cloud for collaboration and data sharing, your team will experience an increased level of data stewardship with maximum uptime and dependability. Also, we can assist your team with the development and deployment of machine learning algorithms allowing users to leverage cloud-based computation for scientific discovery in novel ways.





Semantic Web Data Search and Discovery Platforms
Application of web standard metadata specifications and cloud-based web apps for scientific data search and discovery through Google.
As Technical Officer of the NSF’s EarthCube program, Eric Lingerfelt of Pandia Software led the development and deployment of the GeoCODES data registration, discovery, and access platform. By creating well-formatted JSON-LD markup using the Schema.org metadata standard, you can describe your data so that it is discoverable and accessible to other researchers through Google. Pandia Software can assist your institution with online services, intuitive user interfaces, and databases for automatically generating the markup required for harvesting by Google and other organic search engines. We can also design and develop web apps and eNotebooks that enable users to conduct fine-grained, multi-disciplinary searches across datasets from any scientific domain. By exposing your scientific results and associated metadata, such as citations, measurements and units, geophysical values, and authors through Google, your team’s data will be discoverable, accessible, and sharable with new audiences and could be used by other researchers to enhance their scientific endeavors.



eNotebook Workflow Development
Implementation and deployment of eNotebook technologies for scientific collaboration and data analysis.
The prevalence of eNotebook technology over the past decade has filled a need for interactive user experiences where coding, documentation, user interface widgets, and visualization all integrate for scientific research and collaboration. Our eNotebooks are easy to share and customize, provide stress-free reproducible experiments, and deliver effective learning environments for scientists and students. At Pandia Software, we specialize in eNotebooks written with Jupyter, MATLAB, and R Studio. We can also assist your team with setting up and managing hubs for distributing eNotebooks to students, scientists, and research teams. Our eNotebooks also integrate smoothly with online web and data services and enable users to execute data analysis, machine learning, and simulation codes, visualize datasets, and share well-documented scientific workflows.





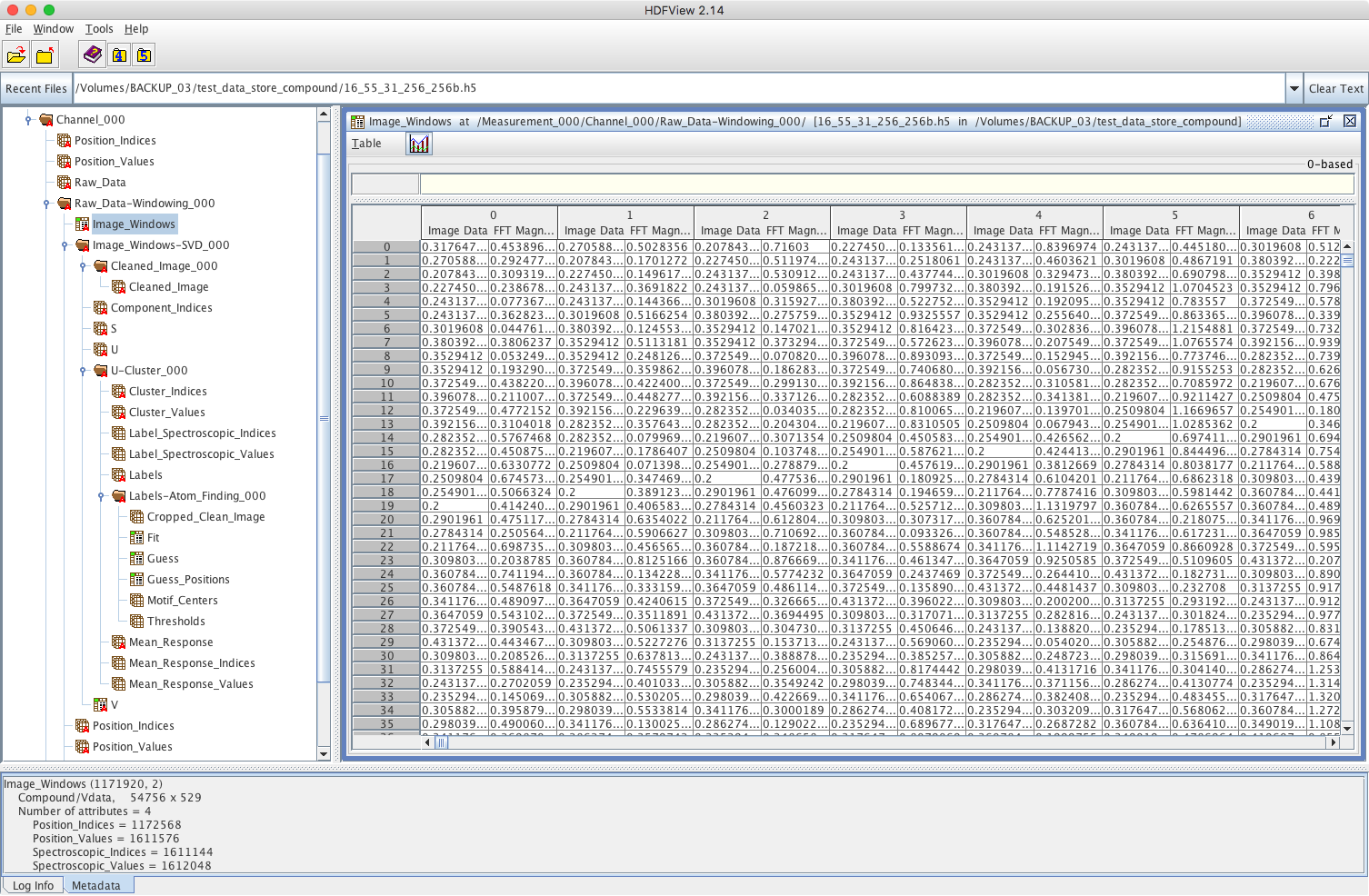
HDF5 Database Design and Utilization
Utilization and configuration of the HDF5 data file format for multidimensional scientific data.
The HDF5 data file format is one of the most common ways to store multidimensional data values for access and manipulation through Java, Python, R, FORTRAN, and other languages as well as commercial products like MATLAB, IDL, and ArcGIS. Organizations use HDF5 for large, heterogeneous datasets due to its efficient subsetting, compression, and “filesystem-in-a-file“ hierarchical structure. It is an open, self-describing format that supports parallel data analysis through effective utilization of data slicing and chunking. Cloud systems like Amazon S3 and cloud-based tools such as Kita enable broad access by internal and external collaborators.
At Pandia Software, we have years of experience designing and configuring HDF5 formats for multiple data types and scientific domains. In addition, our software design process enables quick read and write operations into object-oriented data structures that can be readily accessed by most desktop applications. We design our HDF5 formats to provide easy I/O functions for distributing chucks of data for parallel processing on high performance computing platforms and visualizing pertinent slices of data. We can also assist your team with managing and sharing your HDF5 datasets in the cloud.